 关注
关注 环球网
环球网
 管理员
管理员
 2023-08-17 20:41
2023-08-17 20:41




国内“千模大战”下,谁是最聪明的大模型?《麻省理工科技评论》中国最新发布的大模型评测报告给出了答案。

报告显示,在8个一级大类的600道题目的测试和盲评中,讯飞星火认知大模型V2.0在6个大类中得分率排名第一,在此次评测中表现突出,以 81.5 分(百分制计)的成绩在本次评测中登顶,荣获“最聪明”的国产大模型称号。

图:大模型评测综合得分率
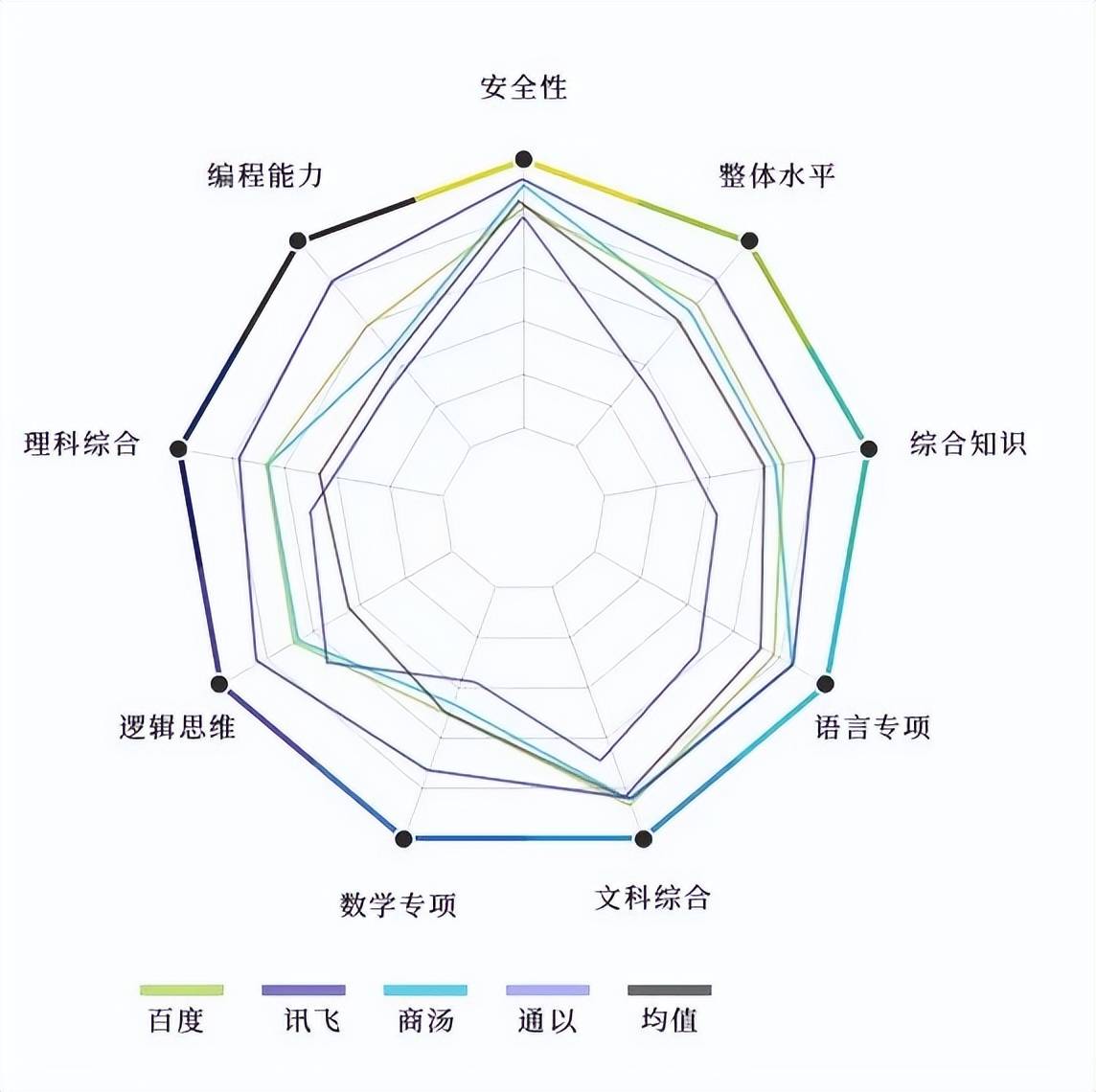
图:4个大模型各项能力雷达图
《麻省理工科技评论》中国从研发和商业化能力、外界态度以及发展趋势等维度全方位检测大模型的能力,力图评出“最聪明”的国产大模型。选取了“讯飞星火”、“百度文心一言”、“商汤商量”、“阿里通义千问”作为中文大模型平台的代表,展开系统、科学的评测。
本次评测使用的测试集包含600道题目,覆盖了语言专项、数学专项、理科综合、文科综合、逻辑思维、编程能力、综合知识、安全性共 8 个一级大类,126 个二级分类,290 个三级标签,并针对问题的丰富性和多样性做了优化。
在题目类型上,为了兼顾定量、定性的评价与测试,设置了“单选”、“多选”、“填空”、“简答”4个题型,分别有 145 道、138 道、136 道和 181 道。大模型评测体系使用盲评方式,客观评估国产大模型的聪明程度。
作为“最聪明”的大模型的基础能力,语言专项评测包含对话理解、多语种、讽刺、古诗词理解、文本生成、要点总结、情感分析、语义判断等 61 个二级分类,题型则以简答为主。结果显示,讯飞星火 85.73%的得分率排名第一,明显高于平均值。
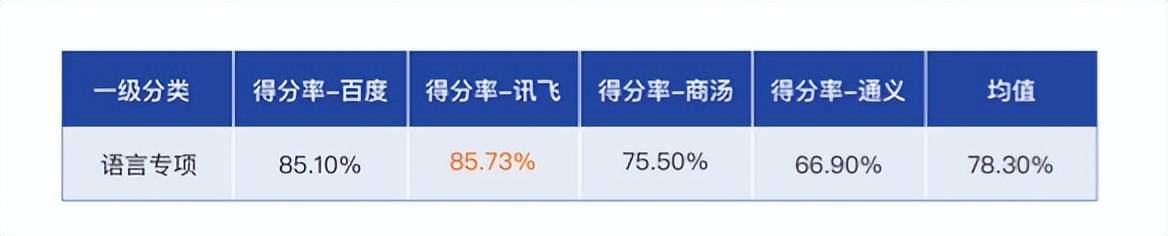
图:语言专项评测得分率
数学专项评测,是“最聪明”大模型必不可少的评测维度。本次评测包含代数、几何、解方程、复杂数学、统计学等 9 个二级分类,以选择题为主。
其中,讯飞星火以 77.75% 的得分率名列第一,远高于平均得分率 56%,其他平台得分率基本相当。报告称,在大模型普遍“数学不好”的情况下,讯飞星火这一成绩颇为难得,其在数学专项上的领先同样体现在二级分类的评分结果上,在 77.8%的二级分类中得分率第一,远超其他平台,初步判断其擅长几何与情景应用。

图:数学专项评测得分率
作为体现大模型“聪明程度”不可或缺的“硬核”部分,理科综合评测包含表格问答、化学、生物、物理、医学 5 个二级分类,题型上以单选和简答为主。
评测结果中,讯飞星火 78.50% 的得分率排名第一。另外,讯飞星火在理科综合大类下 80% 的二级分类评测中得分率为第一,化学与生物较为突出。

图:理科综合评测得分率
逻辑思维也是“最聪明”大模型的重要体现,本次逻辑思维评测在逻辑推理、思维链等方面设计了较多的题目,包含类比、常识推理、空间方位、演绎推理、逻辑谬误检测、因果推理等 19 个二级分类,题型上相对平均,其中填空题最多,多选题最少。
在逻辑思维题目中,讯飞星火 81.25%的得分率名列第一,明显高于 72.6% 的平均值。此外,讯飞星火在逻辑思维 63.2% 的二级分类问题上得分率第一。逻辑思维对于大模型真正理解物理世界相当重要。

图:逻辑思维评测得分率
编程能力是大模型比较高阶的能力,本次的编程能力评测包含 ASCII、ASCII码识别、Python、代码、代码修正、计算机 6 个二级分类,其中 Python 主要以简答形式评估大模型的代码生成能力和正确率,其他则以客观题的形式考察。
结果显示,讯飞星火 80% 的得分率明显高于 71%的平均值,其他平台得分率基本相当。值得一提的是,在许多人关心的生成代码的简答题单项上,讯飞星火的得分率高达 82%,远高于其他平台,表现颇为亮眼。

图:编程能力评测综合得分率
作为比较难的评测维度,综合知识对大模型的“聪明”程度要求也很高,涉及的题目较杂,包含百科问答、常识、科学知识、事实问答、工作技巧、谜语等 13 个二级分类,题型以多选为主。
在综合知识评测上,讯飞星火 80.61% 的得分率排名第一,在 84.6% 的二级分类上得分率第一,初步显示出在百科问答和历史人文上的“过人之处”。
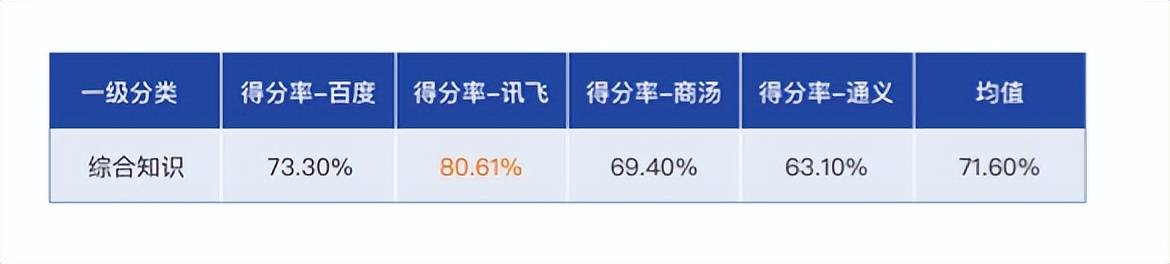
图:综合知识评测得分率
报告指出,在本轮大模型评测中,讯飞星火以 81.5 分的成绩拔得头筹,成为“最聪明”的国产大模型。
讯飞星火在编程能力、理科综合、逻辑思维、数学专项、语言专项和综合知识这 6 个一级大类中得分率排名第一,在此次评测中表现十分全面,尤其是在代码生成、数学能力、理科与逻辑等方面优势明显,是本次“最聪明的理科生”。
值得一提的是,从题型角度来看,主观简答题中讯飞星火凭借 83.98% 的得分率位居第一;而在客观题上,讯飞星火以 75.7% 的得分率排名第一,在主客观体型中均有良好表现。
此外,就在8月12日,新华社研究院中国企业发展研究中心发布的《人工智能大模型体验报告2.0》中,讯飞星火V1.5以总分1013分位列本次国产主流大模型测评榜首位,在四大评测维度中的智商指数和工具提效指数两个维度获得第一,《报告》认为讯飞星火“在工作提效方面优势明显”。
在刚刚过去的8月15日,讯飞星火认知大模型V2.0如期发布,进一步突破代码能力和多模态能力。技术获得重大突破的同时,搭载讯飞星火V2.0核心能力的应用和产品也越来越丰富:既有辅助程序员高效工作的智能编码助手iFlyCode1.0、能够进行视频创作的讯飞智作2.0、能够便捷搭建轻应用的教育数字基座应用开发助手,还有帮助教师设计教学活动、一键生成课件的星火教师助手、面向英语学习者口语练习的星火语伴2.0,讯飞AI学习机也升级AI 1对1智能编程助手和AI 1对1创意绘画伙伴。此外,科大讯飞还和华为联合发布星火一体机,让每一家企业都有机会构建专属大模型。